Table Of Contents
Open Table Of Contents
Different options for different users
Below is the full table of local LLM options and the associated GitHub repo can be found here.
For optimal viewing experience, please use a desktop browser. Mobile users may find some columns hidden due to screen size limitations.
I have split this post into the following sections:
- All-in-one desktop solutions for accessibility
- LLM inference via the CLI and backend API servers
- Front-end UIs for connecting to LLM backends
Each section includes a table of relevant open-source LLM GitHub repos and to gauge popularity and activity.
These projects can overlap in scope and may split into different components of inference backend server and UI. This field evolves quickly, so details may soon be outdated.
#1. Desktop Solutions
All-in-one desktop solutions offer ease of use and minimal setup for executing LLM inferences, highlighting the accessibility of AI technologies. Simply download and launch a .exe or .dmg file to get started. Ideal for less technical users seeking a ready-to-use ChatGPT alternative, these tools provide a solid foundation for anyone looking to explore AI before advancing to more sophisticated, technical alternatives.
Popular Choice: GPT4All
GPT4All is an all-in-one application mirroring ChatGPT’s interface and quickly runs local LLMs for common tasks and RAG. The provided models work out of the box and the experience is focused on the end user.

GPT4All UI realtime demo on M1 MacOS Device (Source)
Open-Source Alternative to LM Studio: Jan
LM Studio is often praised by YouTubers and bloggers for its straightforward setup and user-friendly interface. It offers features like model card viewing, model downloading, and system compatibility checks, making it accessible for beginners in model selection.
Despite its advantages, I hesitate to recommend LM Studio due to its proprietary nature, which may limit its use in business settings because of licensing constraints. Additionally, the inevitable monetization of the product is a concern. I favour open-source solutions when possible.
Jan is an open-source alternative to LM Studio with a clean and elegant UI. The developers actively engage with their community (X and Discord), maintain good documentation, and are transparent with their work - for example, their roadmap.
Jan UI realtime demo: Jan v0.4.3-nightly on a Mac M1, 16GB Sonoma 14 (Source)
With a recent update, you can easily download models from the Jan UI. You can also use any model available from HuggingFace or upload your custom models.
Jan also has a minimal LLM inference server (3 MB) built on top of llama.cpp called nitro, which powers their desktop application.
Feature-Rich: h2oGPT
H2O.ai is an AI company that has greatly contributed to the open-source community with its AutoML products and now their GenAI products. h2oGPT offers extensive features and customization, ideal for NVIDIA GPU owners:
- Many file formats supported for offline RAG
- Evaluation of model performance using reward models
- Agents for Search, Document Q/A, Python code, CSVs
- Robust testing with 1000s of unit and integration tests
You can explore a demo at gpt.h2o.ai to experience the interface before installing it on your system. If the UI meets your needs and you’re interested in more features, a basic version of the app is available for download, offering limited document querying capabilities. For installation, refer to the setup instructions.
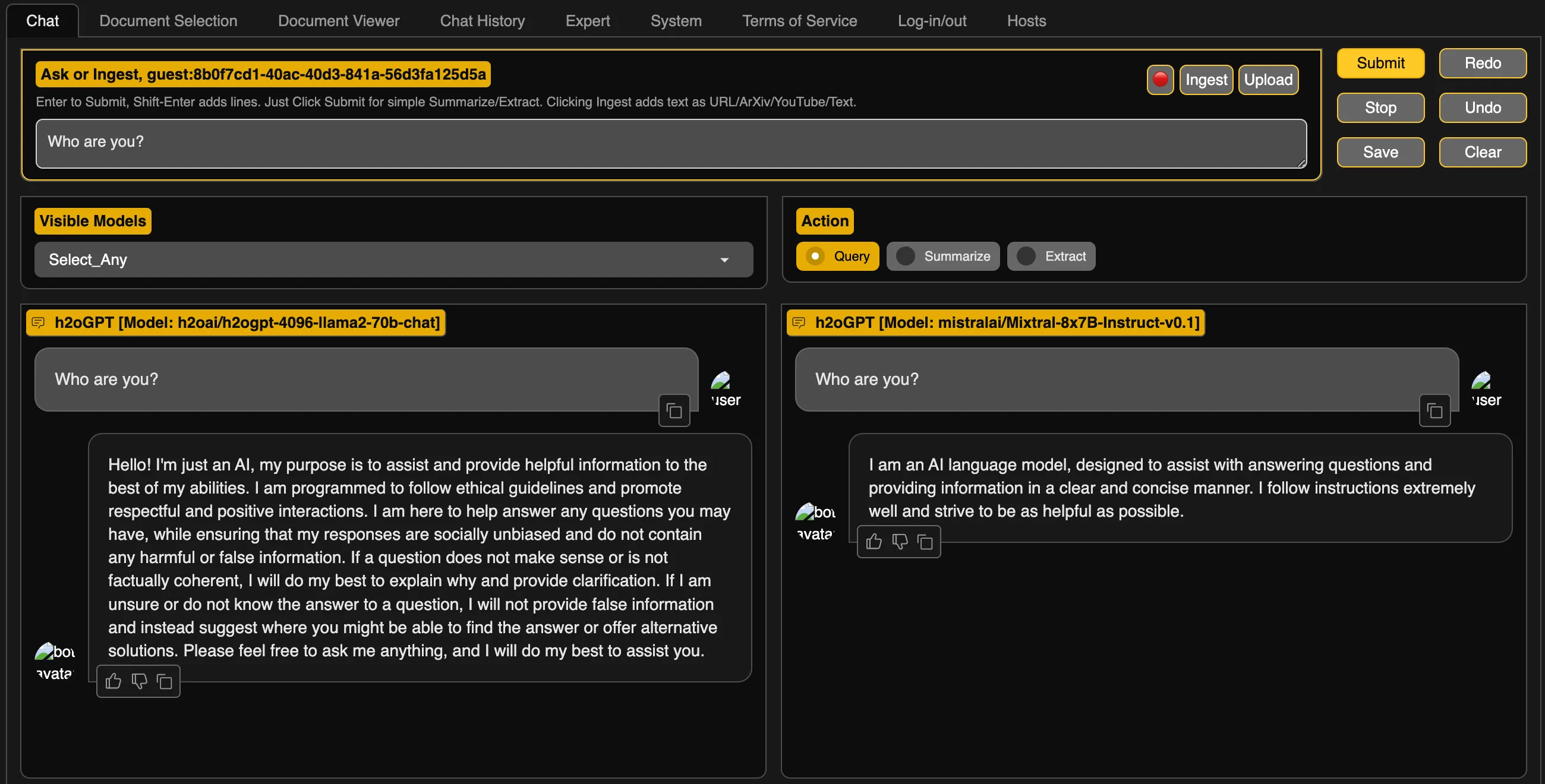
h2oGPT available at https://gpt.h2o.ai/
Other Desktop Solutions
Table of FOSS (Free Open-Source Software) LLM desktop solutions (greater than 5K ⭐):
| Repository Name | About | Stars | Contributors | Issues | Releases |
|---|---|---|---|---|---|
| gpt4all | gpt4all: run open-source LLMs anywhere | 62066 | 85 | 388 | 10 |
| chatbox | Chatbox is a desktop client for ChatGPT, Claude and other LLMs, available on Windows, Mac, Linux | 17425 | 1796 | 28 | 117 |
| jan | Jan is an open source alternative to ChatGPT that runs 100% offline on your computer | 11342 | 36 | 176 | 16 |
| h2ogpt | Private chat with local GPT with document, images, video, etc. 100% private, Apache 2.0. Supports oLLaMa, Mixtral, llama.cpp, and more. Demo: https://gpt.h2o.ai/ https://codellama.h2o.ai/ | 9926 | 66 | 229 | 121 |
| anything-llm | A multi-user ChatGPT for any LLMs and vector database. Unlimited documents, messages, and storage in one privacy-focused app. Now available as a desktop application! | 8717 | 30 | 77 | 0 |
#2. LLM inference via the CLI and backend API servers
CLI tools enable local inference servers with remote APIs, integrating with front-end UIs (listed in Section 3) for a custom experience. They often offer OpenAI API-compatible endpoints for easy model swapping, with minimal code changes.
Although chatbots are the most common use case, you can also use these tools to power Agents, using frameworks such as CrewAI and Microsoft’s AutoGen.
High Optimisation: llama.cpp
llama.cpp offers minimal setup for LLM inference across devices. The project is a C++ port of Llama2 and supports GGUF format models, including multimodal ones, such as LLava. Its efficiency suits consumer hardware and edge devices.

llama.cpp (Source)
There are many bindings based on llama.cpp, like llama-cpp-python (more are listed in the README’s description). Hence, many tools and UIs are built on llama.cpp and provide a more user-friendly interface.
To get started you can follow the instructions here. You will need to download models in GGUF format from HuggingFace.
llama.cpp has its own HTTP server implementation, just type ./server to start.
# Unix-based example
./server -m models/7B/ggml-model.gguf -c 2048
This means you can easily connect it with other web chat UIs, listed in section 2.
This option is best for those who are comfortable with the command line interface (CLI) and prefer writing custom scripts and seeing outputs in the terminal.
Intuitive CLI Option: Ollama
Ollama is another LLM inference command-line tool - built on top of llama.cpp and abstracts scripts into simple commands. Inspired by Docker, it offers simple and intuitive model management, making it easy to swap models. You can see the list of available models at https://ollama.ai/library. You can also run any GGUF model from HuggingFace following these instructions.
Ollama (Source)
Once you have followed the instructions to download the Ollama application. You can run simple inferences in the terminal by running:
ollama run llama2
A useful general heuristic for selecting model sizes from Ollama’s README:
You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
By default, Ollama uses 4-bit quantization. To try other quantization levels, try the other tags. The number after the q represents the number of bits used for quantization (i.e. q4 means 4-bit quantization). The higher the number, the more accurate the model is, but the slower it runs, and the more memory it requires.
With ollama serve, Ollama sets itself up as a local server on port 11434 that can connect with other services. The FAQ provides more information.
Ollama stands out for its strong community support and active development, with frequent updates driven by user feedback on Discord. Ollama has many integrations and people have developed mobile device compatibility.
Other LLM Backend Options
Table of LLM inference repos (greater than 1K ⭐):
| Repository Name | About | Stars | Contributors | Issues | Releases |
|---|---|---|---|---|---|
| transformers | 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. | 121,481 | 434 | 1,011 | 141 |
| llama.cpp | LLM inference in C/C++ | 52,335 | 479 | 1,207 | 1,499 |
| ollama | Get up and running with Llama 2, Mistral, Gemma, and other large language models. | 44,732 | 143 | 779 | 50 |
| mlc-llm | Enable everyone to develop, optimize and deploy AI models natively on everyone’s devices. | 16,103 | 92 | 199 | 1 |
| vllm | A high-throughput and memory-efficient inference and serving engine for LLMs | 15,627 | 212 | 1,281 | 21 |
| llamafile | Distribute and run LLMs with a single file. | 9,736 | 27 | 42 | 10 |
| llama-cpp-python | Python bindings for llama.cpp | 5,836 | 117 | 117 | 305 |
| koboldcpp | A fast inference library for running LLMs locally on modern consumer-class GPUs | 2,594 | 28 | 101 | 14 |
| exllamav2 | Access large language models from the command-line | 2,512 | 19 | 135 | 24 |
| llm | Access large language models from the command-line | 2,512 | 19 | 135 | 24 |
#3. Front-end UIs for connecting to LLM backends
The tools discussed in Section 2 can handle basic queries using the pre-trained data of LLMs. Yet, their capabilities significantly expand with integrating external information via web search and Retrieval Augmented Generation (RAG). Utilizing user interfaces that leverage existing LLM frameworks, like LangChain and LlamaIndex, simplifies embedding data chunks into vector databases.
The UIs mentioned in this section seamlessly interface with the backend servers set up with Section 1’s tools. They are compatible with various APIs, including OpenAI’s, allowing easy integration with proprietary and open weights models.
Most similar to ChatGPT visually and functionally: Open WebUI
Open WebUI is a web UI that provides local RAG integration, web browsing, voice input support, multimodal capabilities (if the model supports it), supports OpenAI API as a backend, and much more. Previously called ollama-webui, this project is developed by the Ollama team.
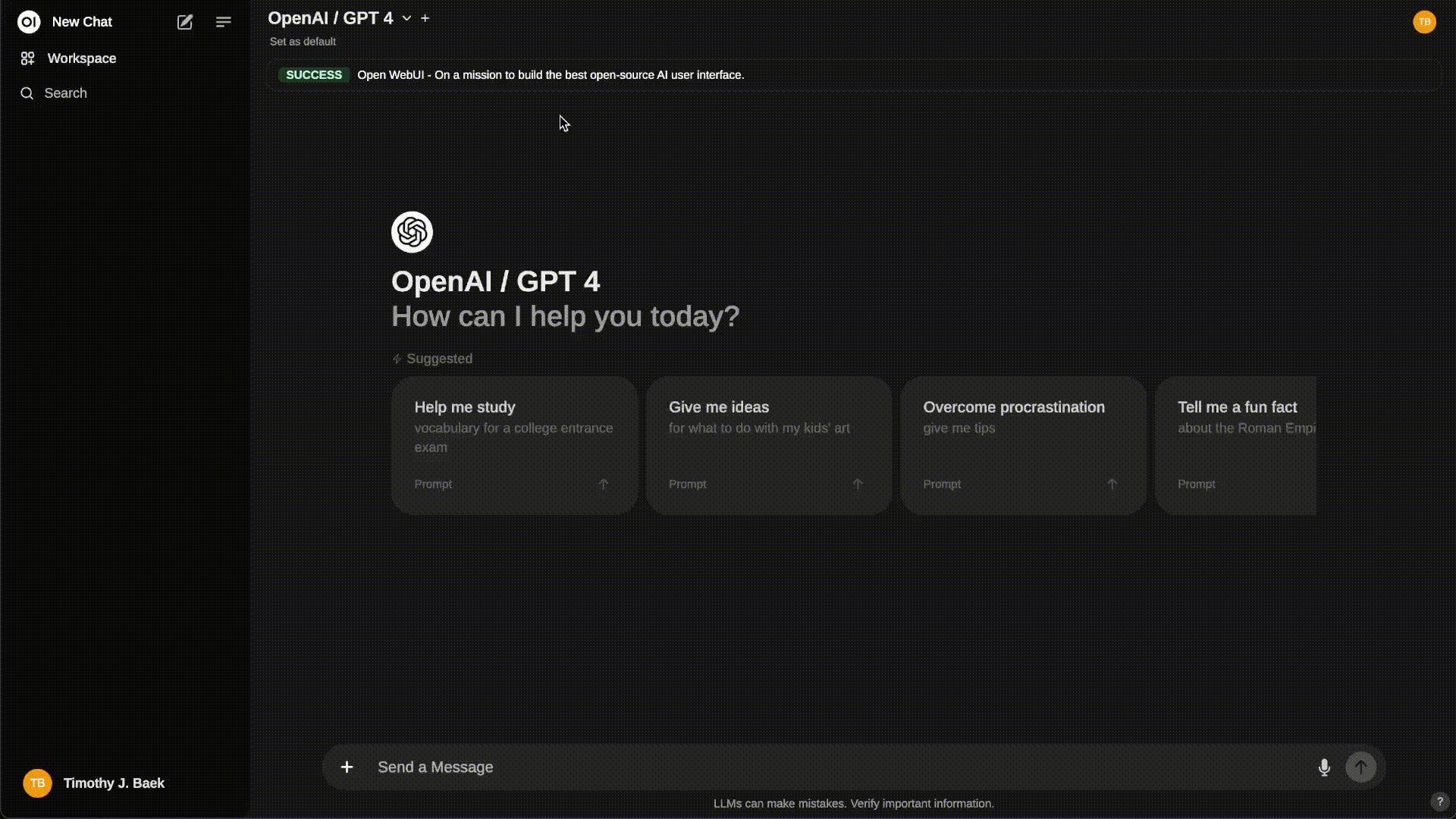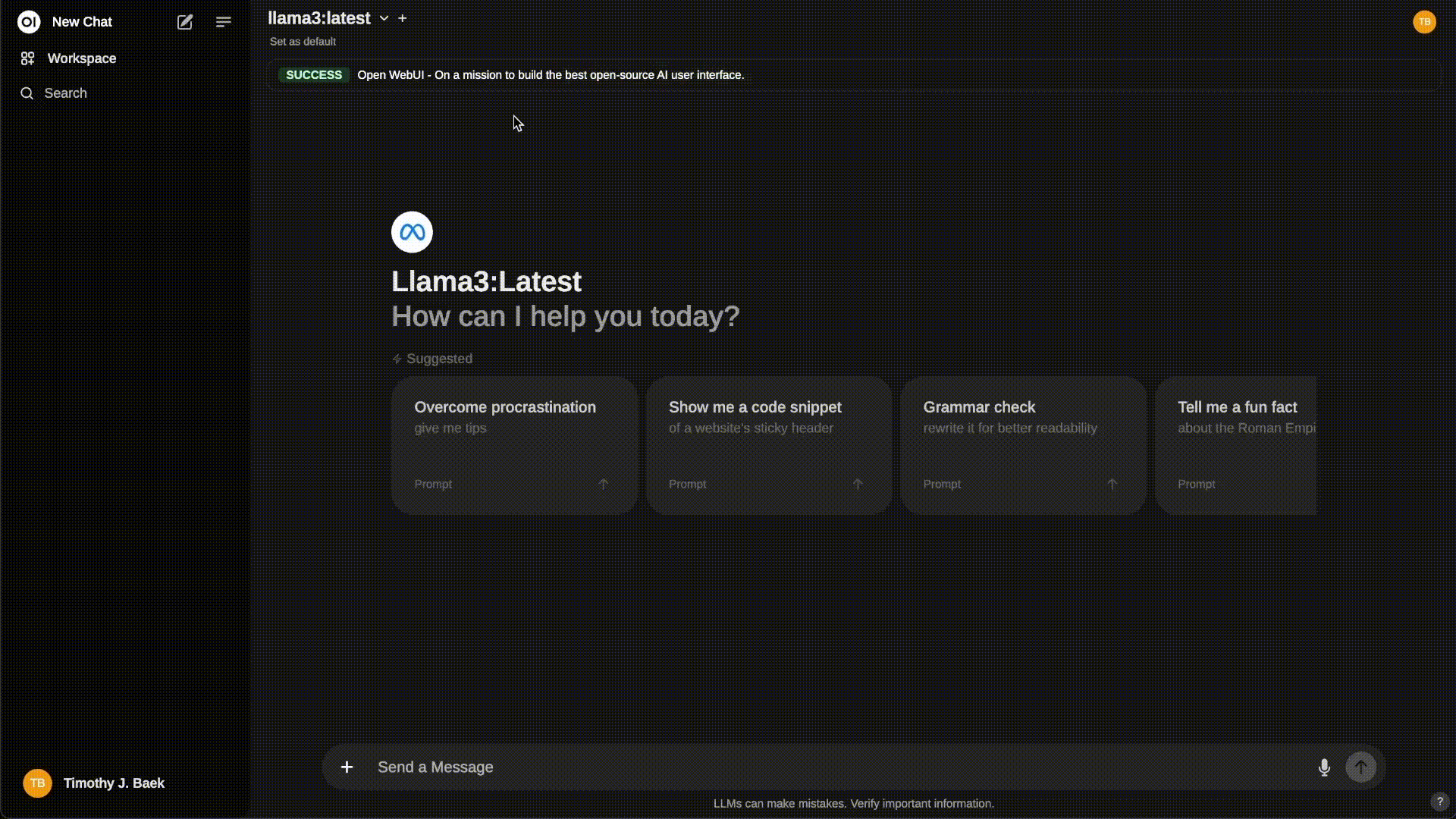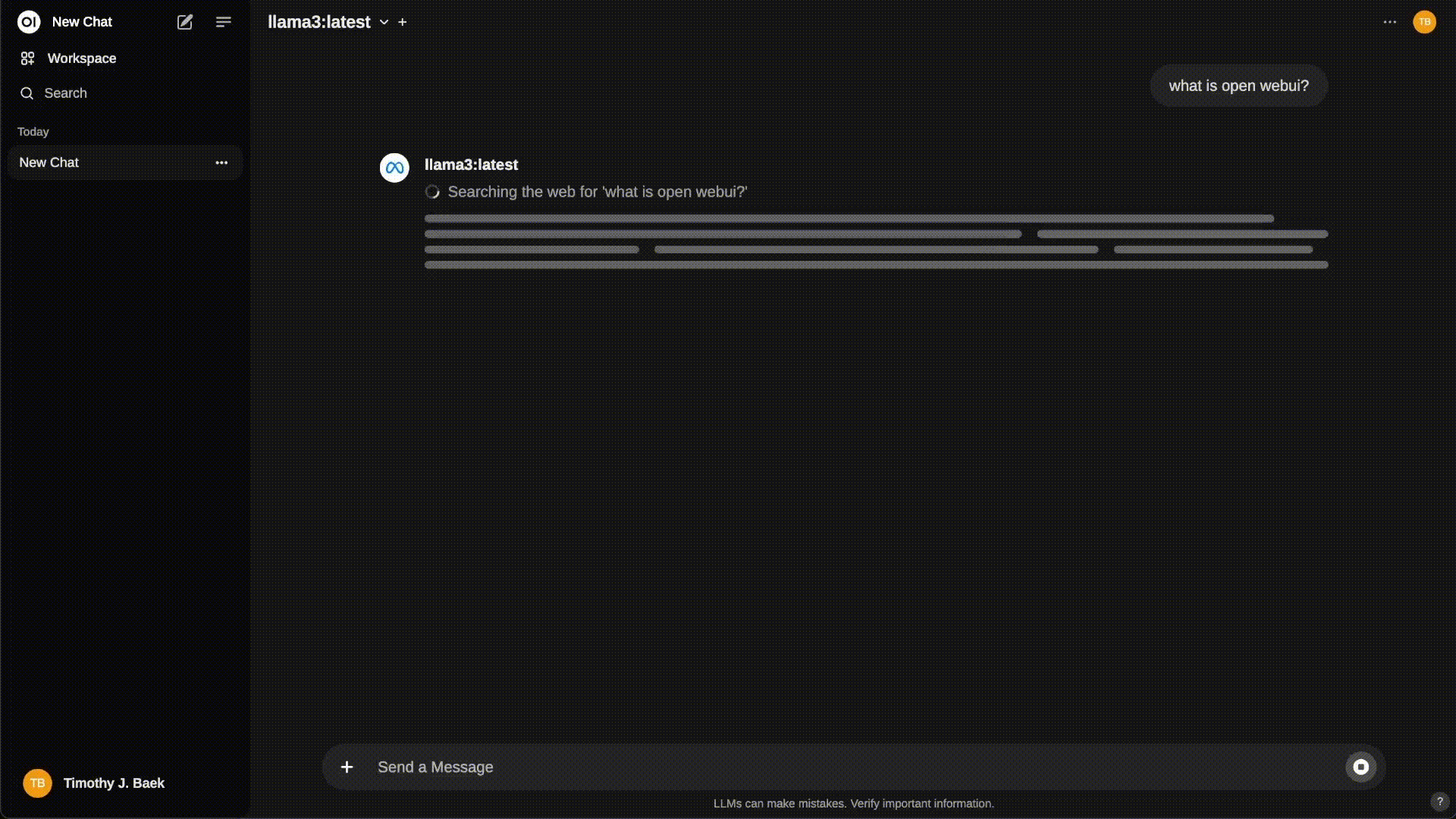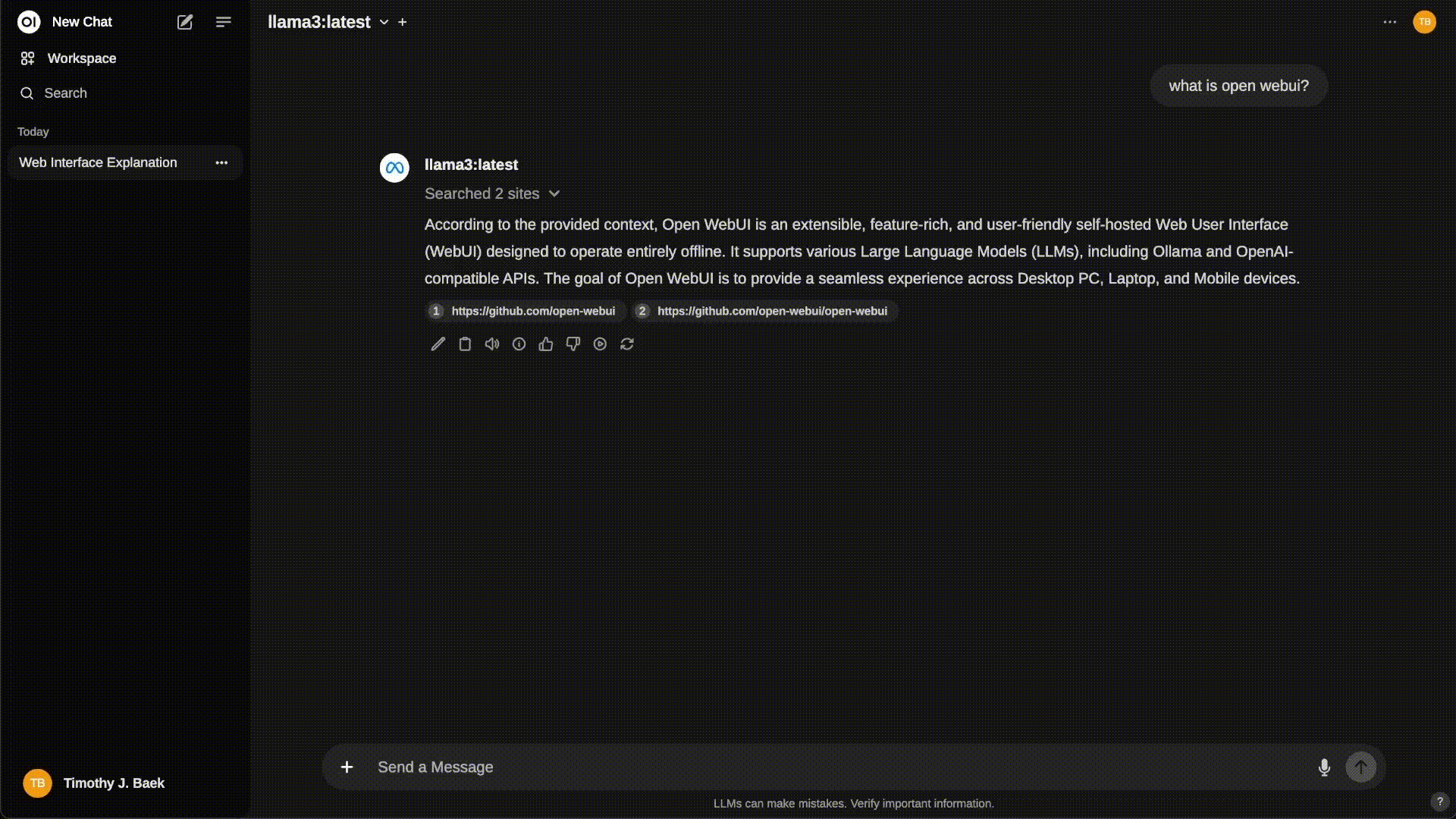
OpenWeb UI demo (Source)
To connect Open WebUI with Ollama all you need is Docker already installed, and then simply run the following:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Then you can simply access Open WebUI at http://localhost:3000.
Feature Rich UI: Lobe Chat
Lobe Chat has more features, including its Plugin System for Function Calling and Agent market. Plugins include search engines, web extraction, and many custom ones from the community. Their prompt agent market is similar to the ChatGPT market, which allows users to share and optimize prompt agents for their own use.
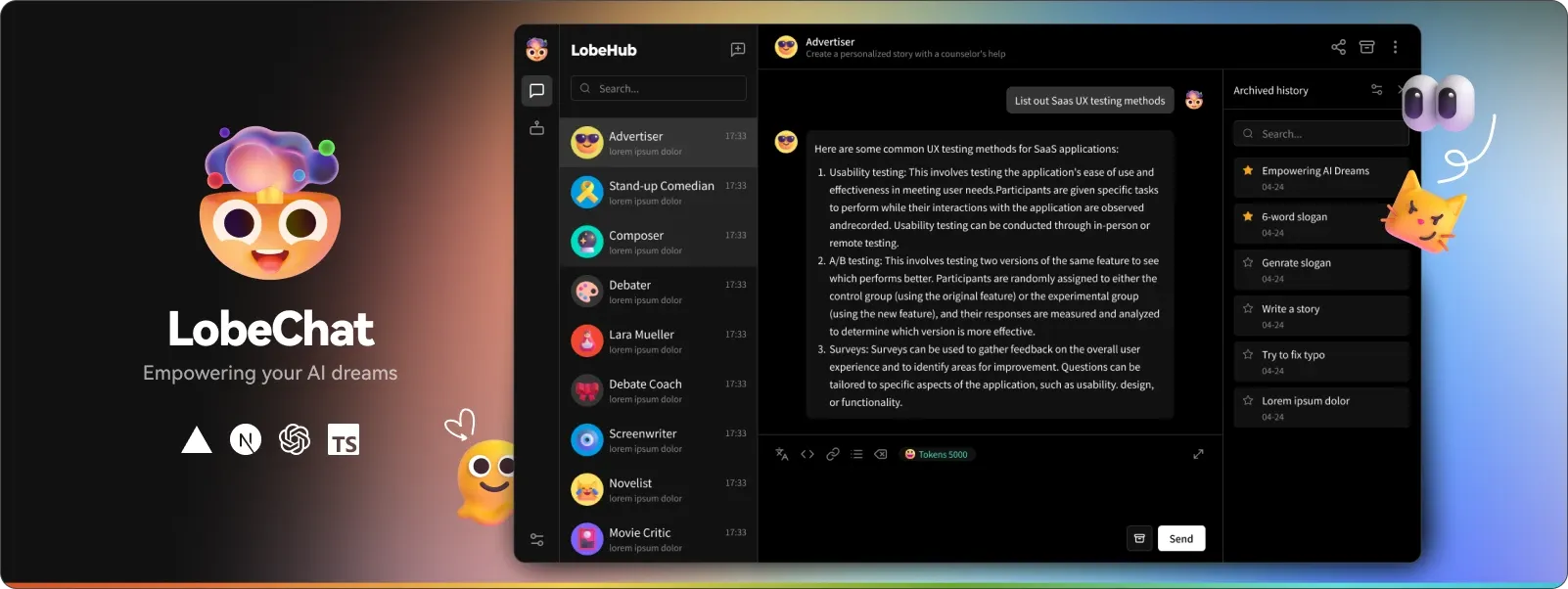
Lobe Chat UI (Source)
To start a Lobe Chat conversation with a local LLM with Ollama, simply use Docker:
docker run -d -p 3210:3210 -e OLLAMA_PROXY_URL=http://host.docker.internal:11434/v1 lobehub/lobe-chat
Then you can simply access Lobe Chat at http://localhost:3210. Read here for more information.
UI that supports many backends: text-generation-webui
text-generation-webui by Oogabooga is a fully featured Gradio web UI for LLMs and supports many backend loader such as transformers, GPTQ, autoawq (AWQ), exllama (EXL2), llama.cpp (GGUF), and Llama models - which are refactors of the transformers code libraries with extra tweaks.
 |  |
|---|---|
 |  |
text-generation-webui UIs and settings (Source)
text-generation-webui is highly configurable and even offers finetuning with QLoRA due to its transformers backend. This allows you to enhance a model’s capabilities and customize based on your data. There is thorough documentation on their wiki. I find this option useful for quickly testing models due to its great out-of-the-box support.
Other UI Options
Table of UIs (greater than 5K ⭐):
| Repository Name | About | Stars | Contributors | Issues | Releases |
|---|---|---|---|---|---|
| ChatGPT-Next-Web | A cross-platform ChatGPT/Gemini UI (Web / PWA / Linux / Win / MacOS). | 63,543 | 166 | 216 | 57 |
| privateGPT | Interact with your documents using the power of GPT, 100% privately, no data leaks | 48,180 | 59 | 136 | 5 |
| text-generation-webui | A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. | 33,828 | 299 | 280 | 33 |
| lobe-chat | 🤯 Lobe Chat - an open-source, modern-design LLMs/AI chat framework. Supports Multi AI Providers( OpenAI / Claude 3 / Gemini / Perplexity / Bedrock / Azure / Mistral / Ollama ), Multi-Modals (Vision/TTS) and plugin system. One-click FREE deployment of your private ChatGPT chat application. | 21443 | 68 | 179 | 452 |
| localGPT | Chat with your documents on your local device using GPT models. No data leaves your device and 100% private. | 18,661 | 42 | 441 | 0 |
| LocalAI | :robot: The free, Open Source OpenAI alternative. Self-hosted, community-driven and local-first. Drop-in replacement for OpenAI running on consumer-grade hardware. No GPU required. Runs gguf, transformers, diffusers and many more models architectures. It allows to generate Text, Audio, Video, Images. Also with voice cloning capabilities. | 17,320 | 75 | 242 | 37 |
| open-webui | User-friendly WebUI for LLMs (Formerly Ollama WebUI) | 8,489 | 64 | 73 | 9 |
| LibreChat | Enhanced ChatGPT Clone: Features OpenAI, Assistants API, Azure, Groq, GPT-4 Vision, Mistral, Bing, Anthropic, OpenRouter, Google Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure Multi-User System, Presets, completely open-source for self-hosting. More features in development | 8,410 | 84 | 64 | 36 |
| openplayground | An LLM playground you can run on your laptop | 6,008 | 16 | 76 | 0 |
| chat-ui | Open source codebase powering the HuggingChat app | 5,470 | 52 | 170 | 5 |
| SillyTavern | LLM Frontend for Power Users. | 5,159 | 88 | 255 | 73 |
Conclusion: What I use and recommend
I’ve been using Ollama for its versatility, easy model management, and robust support, especially its seamless integration with OpenAI models. For coding, Ollama’s API connects with the continue.dev VS Code plugin, replacing GitHub Copilot.
For UIs, I prefer Open WebUI for its professional, ChatGPT-like interface, or Lobe Chat for additional plugins. For those seeking a user-friendly desktop app akin to ChatGPT, Jan is my top recommendation.
I use both Ollama and Jan for local LLM inference, depending on how I wish to interact with an LLM. You can integrate Ollama and Jan to save system storage and avoid model duplication.
Enjoying the content? Follow me on Medium or support my work with a coffee!