Every ML engineer has faced that moment: staring at a complex problem, knowing someone somewhere must have solved this before. ‘Machine Learning Design Patterns’ is the book I wish I had during those moments. It captures the collective wisdom of thousands of ML implementations, and I’ve documented the key insights here to help fellow practitioners avoid reinventing the wheel.
The Book In Three Sentences
- The book is a catalogue of 30 machine learning (ML) design patterns (repeatable solutions) that capture best practices and solutions to commonly occurring ML engineering problems.
- For each pattern, the authors provide a comprehensive exploration including a problem statement, solution, detailed explanation, and discussions of trade-offs and alternative approaches.
- The authors bring exceptional credibility to these patterns, having developed thousands of ML solutions as solution architects in Google Cloud’s Field Technology team, serving hundreds of customers across diverse industries.
What Are Design Patterns?
Design patterns are proven solutions to common engineering problems, distilled from expert experience. Interestingly, the term ‘design patterns’ has its roots in architecture, where it helped architects avoid reinventing established principles.
These patterns transform unspoken knowledge into structured solutions with clear names, enabling practitioners to learn, communicate, and problem-solve more effectively.
Why I Like This Book
What makes this book exceptional is its pragmatic approach. Rather than promising perfect solutions, it embraces the complexity of real-world ML systems and guides you through making informed trade-offs based on practical experience.
Who Is The Book For?
This isn’t another ML textbook explaining the mechanics of random forests. Instead, it’s a practical guide that assumes foundational knowledge and focuses on the crucial ‘why’ behind ML engineering decisions.
How I Came Across This Book
My friend Kev recommended this book after successfully applying several of its patterns in his MLE role, particularly the cascade design pattern.
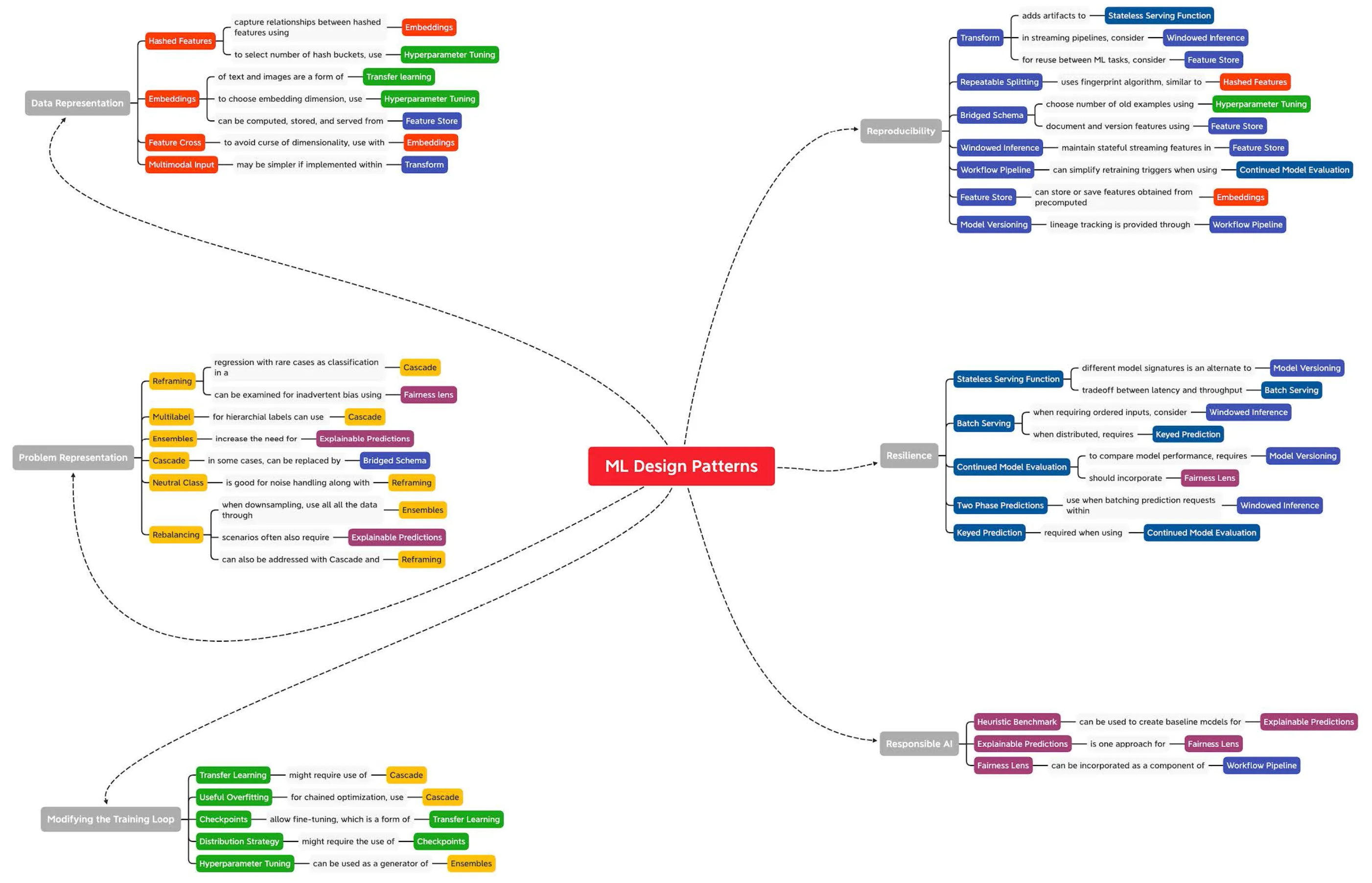
Pattern Interactions - How They All Link Together
The chart below from the book shows the interdependencies and relationships between different design patterns. Some patterns naturally complement other patterns.
For instance, when handling text data (a high-cardinality input), you might combine the Hashed Feature pattern for dimensionality reduction with the Embeddings pattern for semantic understanding.
Patterns Reference
Here is a summary of the patterns used in the book.
Chapter 1. Data Representation
| Design Pattern | Problem Solved | Solution |
|---|---|---|
| #1 Hashed Feature | Problems associated with categorical features such as incomplete vocabulary, model size due to cardinality, and cold start. | Bucket a deterministic and portable hash of string representation and accept the trade-off of collisions in the data representation. |
| #2 Embeddings | High-cardinality features where closeness relationships are important to preserve. | Learn a data representation that maps high-cardinality data into a lower-dimensional space while preserving relevant information. |
| #3 Feature Cross | Model complexity insufficient to learn feature relationships. | Help models learn relationships between inputs faster by explicitly making each combination of input values a separate feature. |
| #4 Multimodal Input | How to choose between several potential data representations. | Concatenate all the available data representations. |
Chapter 2. Problem Representation
| Design Pattern | Problem Solved | Solution |
|---|---|---|
| #5 Reframing | Several problems including confidence for numerical prediction, ordinal categories, restricting prediction range, and multitask learning. | Change the representation of the output of a machine learning problem; for example, representing a regression problem as a classification (and vice versa). |
| #6 Multilabel | More than one label applies to a given training example. | Encode the label using a multi-hot array, and use K sigmoids as the output layer. |
| #7 Ensembles | Bias–variance trade-off on small- and medium-scale problems. | Combine multiple machine learning models and aggregate their results to make predictions. |
| #8 Cascade | Maintainability or drift issues when a machine learning problem is broken into a series of ML problems. | Treat an ML system as a unified workflow for the purposes of training, evaluation, and prediction. |
| #9 Neutral Class | The class label for some subset of examples is essentially arbitrary. | Introduce an additional label for a classification model, disjoint from the current labels. |
| #10 Rebalancing | Heavily imbalanced data. | Downsample, upsample, or use a weighted loss function depending on different considerations. |
Chapter 3. Patterns That Modify Model Training
| Design Pattern | Problem Solved | Solution |
|---|---|---|
| #11 Useful Overfitting | Using machine learning methods to learn a physics-based model or dynamical system. | Forgo the usual generalization techniques in order to intentionally overfit on the training dataset. |
| #12 Checkpoints | Lost progress during long-running training jobs due to machine failure. | Store the full state of the model periodically, so that partially trained models are available and can resume training from an intermediate point instead of starting from scratch. |
| #13 Transfer Learning | Lack of large datasets needed to train complex machine learning models. | Take part of a previously trained model, freeze the weights, and use these non-trainable layers in a new model that solves a similar problem. |
| #14 Distribution Strategy | Training large neural networks can take a very long time, which slows experimentation. | Carry the training loop out at scale over multiple workers, taking advantage of caching, hardware acceleration, and parallelization. |
| #15 Hyperparameter Tuning | How to determine the optimal hyperparameters of a machine learning model. | Insert the training loop into an optimization method to find the optimal set of model hyperparameters. |
Chapter 4. Resilience
| Design Pattern | Problem Solved | Solution |
|---|---|---|
| #16 Stateless Serving Function | Production ML systems must handle thousands to millions of prediction requests per second. | Export the machine learning model as a stateless function so that it can be shared by multiple clients in a scalable way. |
| #17 Batch Serving | Carrying out model predictions over large volumes of data using an endpoint that handles requests one at a time will overwhelm the model. | Use distributed data processing infrastructure to carry out inference asynchronously on a large number of instances. |
| #18 Continued Model Evaluation | Model performance degrades over time due to data drift, concept drift, or changes to pipelines feeding the model. | Detect when a deployed model is no longer fit-for-purpose by continually monitoring model predictions and evaluating model performance. |
| #19 Two-Phase Predictions | Large, complex models must be kept performant when deployed at the edge or on distributed devices. | Split the use case into two phases with only the simpler phase being carried out on the edge. |
| #20 Keyed Predictions | How to map model predictions to their corresponding inputs when submitting large prediction jobs. | Allow the model to pass through a client-supported key during prediction that can be used to join model inputs to model predictions. |
Chapter 5. Reproducibility
| Design Pattern | Problem Solved | Solution |
|---|---|---|
| #21 Transform | Inputs to a model must be transformed consistently between training and serving. | Explicitly capture and store the transformations applied to convert the model inputs into features. |
| #22 Repeatable Splitting | When creating data splits, it is important to have a method that is lightweight and repeatable. | Identify a column that captures the correlation relationship between rows and use hashing algorithms to split the available data into training, validation, and testing datasets. |
| #23 Bridged Schema | Changes to data schema prevent using both the new and old data for retraining. | Adapt the data from its older, original data schema to match the schema of the newer, better data. |
| #24 Windowed Inference | Some models require aggregated features across a time window while avoiding training-serving skew. | Externalize the model state and invoke the model from a stream analytics pipeline to ensure features calculated dynamically are consistent between training and serving. |
| #25 Workflow Pipeline | When scaling ML workflows, run trials independently and track performance for each step of the pipeline. | Make each step of the ML workflow a separate, containerized service that can be chained together to form a pipeline that can be run with a single REST API call. |
| #26 Feature Store | Ad hoc feature engineering slows development and leads to duplicated effort between teams. | Create a feature store, a centralized location to store and document feature datasets that can be shared across projects and teams. |
| #27 Model Versioning | It is difficult to monitor performance and update models in production without breaking existing users. | Deploy a changed model as a microservice with a different REST endpoint to achieve backward compatibility for deployed models. |
Chapter 6. Responsable AI
| Design Pattern | Problem Solved | Solution |
|---|---|---|
| #28 Heuristic Benchmark | Explaining model performance using complicated metrics does not provide intuition for business decision-makers. | Compare an ML model against a simple, easy-to-understand heuristic. |
| #29 Explainable Predictions | Debugging or compliance often requires understanding why a model makes certain predictions. | Apply model explainability techniques to improve user trust in ML systems. |
| #30 Fairness Lens | Bias in datasets or models can have adverse effects on certain populations. | Use tools to identify bias in datasets before training and evaluate trained models through a fairness lens to ensure equitable predictions across different groups. |
Common Patterns by Use Case and Data Type
| Embeddings | |||||
| Hashed Feature | |||||
| Neutral Class | |||||
| Multimodal Input | |||||
| Transfer Learning | |||||
| Two-Phase Predictions | |||||
| Cascade | |||||
| Windowed Inference | |||||
| Reframing | |||||
| Feature Store | |||||
| Feature Cross | |||||
| Ensemble | |||||
| Transform | |||||
| Multilabel | |||||
| Batch Serving | |||||
| Rebalancing |
Before You Start Training Any Models - Heuristic Benchmarks
Before building any machine learning models, you should always first set a heuristic benchmark that is simple and easy to understand, so you can explain the model’s performance to business decision makers.
A good heuristic benchmark should be intuitively easy to understand and compute. Good examples of benchmarks are constants, rules of thumbs, or bulk statistics (like mean, median, and mode). However, don’t use a heuristic benchmark if there already is an operational practice. Instead, compare your model to that existing standard.
| Scenario | Heuristic Benchmark | Example Task | Implementation for Example Task |
|---|---|---|---|
| Regression problem where features and interactions between features are not well understood by the business | Mean or median value of the label value over the training data. | Time interval before a question on Stack Overflow is answered. | Predict that it will be 2,120 seconds always. Use the median time to first answer over the entire training dataset. |
| Binary classification problem where features and interactions between features are not well understood by the business | Overall fraction of positives in the training data. | Whether or not an accepted answer in Stack Overflow will be edited. | Predict 0.36 as the fraction of accepted answers overall that are edited. |
| Multilabel classification problem where features and interactions between features are not well understood by the business | Distribution of the label value over the training data. | Country from which a Stack Overflow question will be answered. | Predict 0.3 for France, 0.05 for India, and so on. These are fractions of answers written by people from France, India, etc. |
| Regression problem where there is a single, very important, numeric feature | Linear regression based on what is, intuitively, the single most important feature. | Predict taxi fare amount given pickup and dropoff locations. | The distance between the two points is, intuitively, a key feature. The fare = $4.64 per kilometer. |
| Regression problem with one or two important features. The features could be numeric or categorical but should be commonly used heuristics. | Lookup table where the rows and columns correspond to the key features (discretized if necessary) and the prediction for each cell is the average label in that cell over the training data. | Predict duration of bicycle rental. | Here, the two key features are the stations that the bicycle is being rented from and whether or not it is peak hours for commuting. |
| Classification problem with one or two important features. The features could be numeric or categorical. | As above, except that the prediction for each cell is the distribution of labels in that cell. If the goal is to predict a single class, compute the mode of the label in each cell. | Predict whether a Stack Overflow question will get answered within one day. | For each tag, compute the fraction of questions that are answered within one day. |
| Regression problem that involves predicting the future value of a time series | Persist linear trend. Take seasonality into account. For annual data, compare against the same day/week/quarter of the previous year. | Predict weekly sales volume. | Predict that next week’s sales = x₀ where x₀ is the sales this week (or) Next week’s sales = x₀ + (x₀ - x₁) where x₁ is last week’s sales. |
| Classification problem currently being solved by human experts. This is common for image, video, and text tasks and includes scenarios where it is cost-prohibitive to routinely solve the problem with human experts. | Performance of human experts. | Detecting eye disease from retinal scans. | Have three or more physicians examine each image. Treat the decision of a majority of physicians as being correct, and look at the percentile ranking of the ML model among the human experts. |
| Preventive or predictive maintenance | Perform maintenance on a fixed schedule. | Preventive maintenance of a car. | Bring cars in for maintenance once every three months. Use the median time to failure of cars from the last service date. |
| Anomaly detection | 99th percentile value estimated from the training dataset. | Identify a denial of service (DoS) attack from network traffic. | Find the 99th percentile of requests per minute in the historical data. If over any one-minute period, the number of requests exceeds this number, flag it as a DoS attack. |
| Recommendation model | Recommend the most popular item in the category of the customer’s last purchase. | Recommend movies to users. | If a user just saw (and liked) Inception (a sci-fi movie), recommend Icarus to them (the most popular sci-fi movie they haven’t yet watched). |
Final Thoughts
‘Machine Learning Design Patterns’ stands as the most actionable resource I’ve encountered for solving real-world ML challenges. While the solutions often lean toward Google Cloud implementations, the underlying principles remain valuable across all platforms. The patterns themselves are technology-agnostic, and the authors thoughtfully include open-source alternatives throughout.
The true strength of this book lies in its practical wisdom - the kind that usually takes years of experience to accumulate. For practitioners looking to transform complex ML engineering challenges into manageable, repeatable solutions, this resource is invaluable. I expect to reference these patterns frequently as I tackle new ML challenges.
References
- Machine Learning Design Patterns by Valliappa Lakshmanan, Sara Robinson, and Michael Munn.
- The book’s official GitHub repo