
🎉 One Month in Singapore’s AI Scene 🤖
Published:
It’s been an action-packed first month in Singapore for me, settling into the new country and immersing myself in the vibrant AI community here! Here’s an overview of what I’ve been up to and my main takeaways from 24 hours of meetups and conferences on Generative AI, Machine Learning for finance, and Data Engineering.
These events were on the following topics:
- 27 Jul - Autonomous Agents with Large Language Models (LLMs)
- 28 Jul - Generative AI: Improving Patient Care with AI and LLMs
- 01 Aug - Data Tuesdays #1
- 02 Aug - World AI Show
- 02 Aug - dbt meetup
- 03 Aug - How to break into AI Careers
- 16 Aug - OCBC Data Engineering Revolution
- 18 Aug - BrightRaven.ai launch party
- 21 Aug - Application of ML and GenAI in Finance
- 29 Aug - Data Tuesday #2 - Quantum Computing
- 31 Aug - Why Vector Search is Important

Members at the first ever Data Tuesday Singapore. Photo by Ville
27th July - 🤖 Autonomous Agents with Large Language Models (LLMs) at Google Developers Space
At Machine Learning Singapore’s event, Sam Witteveen from RedDragon.ai’s presented:
- How to build LLM agents that can make their own decisions and act upon them.
- How these agents have components which differ from the typical LLM stack, such as planning / task orchestration, self-reflection, and data ingestion with browser interaction tools such as MultiOn and browserless.io.
- His own example of a business email agent that can send 1000s of cold emails and generate replies that push the recipient towards a desired outcome.
- Existing agents such as Auto-GPT, BabyAGI, and GPT Engineer.
- How we will likely see a future of multi-agents - where several agents are working together and there being a universal language between them, i.e. specific APIs developed for bots/agents rather than broad APIs designed for developers.
Sam’s YouTube channel is a goldmine for anyone keen on the latest GenAI developments.
Martin Andrews, fellow co-founder, shared:
- How you can incrementally improve LLM-powered agents though:
- Fine-tuning - using methods such as Parameter Efficient Fine-Tuning (PEFT), Low-Rank Adaption of LLMs (LoRA), and Mixture of LoRAs (MoLoRA)
- Self-critiquing - self-refinement, self-debug, and self-reflection
- Tool use - such as using a search tool for ReAct
- However, the real improvements in Open-Ended tasks / systems will come from innovation and not incrementalism. Martin provided the fun thought experiment of reaching the moon - you wouldn’t focus on a ladder, a red herring, and incrementally building it higher, instead you would need to explore unknown areas and innovate (novelty search), which in hindsight may lead to the goal.
Check out Martin’s insightful presentation at https://redcatlabs.com/2023-07-27_MLSG_OpenEnded/#/openended-talk.
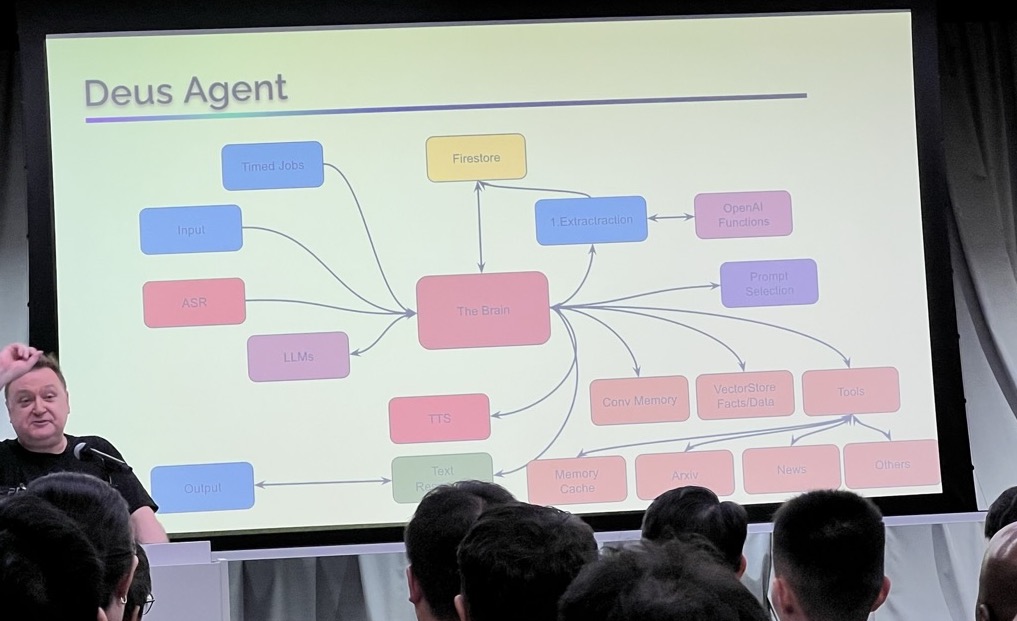
Sam presenting Autonomous Agents with LLM
Sam presenting Autonomous Agents with LLMs
28th July - 🏥 Generative AI: Improving Patient Care with AI and LLMs
H2O.ai hosted a session on Real-life use-cases of Generative AI: Improving Patient Care with AI and LLMs. Jong Hang demonstrated 4 practical examples in the hospital and military sectors and how you can use chain-of-thought prompting for instruction design to combat hallucinations and ensure the GPT only answers questions within its domain / task.
Vishal Sharma showcased two open-source H2O.ai tools:
- h2oGPT - harness LLM’s fine-tuned by the world’s best Kaggle Grandmasters. Have a play online at https://gpt.h2o.ai/ or clone and run locally at https://github.com/h2oai/h2ogpt.
- LLM Studio for fine-tuning your LLMs in a no-code GUI with your own data, with LoRA, QLoRA, and even Reinforced Learning from Human Feedback (RLHF). Available to clone at https://github.com/h2oai/h2o-llmstudio.
1st August - 💽 Data Tuesday #1
Kicked off the first-ever Data Tuesday by Ville Kulmala. It’s a relaxed space for genuine data discussions, you’ll know where to find me every month!
2nd & 3rd August - 🌏 World AI Show at the Marina Bay Sands Exhibition Center
It’s hard to summarise the 14 talks I attended across the two day AI conference (this could easily have its own blog post). The standout session for me was the panel discussion on AI and Data Driven Decision Making between Robert Hollinger, Adrien Chenailler, Jeannette Pang, and Ram Thilak. They explained how they are making an impact for their customers in the banking and automotive sectors with AI and ML through:
- Fraud / anomaly detection
- Real-time recommendations, price positions, and personalisations for product offerings
- Operational chatbots
- Churn prediction
- Building dashboards that answer real questions
Underpinning all this, I was glad to hear how much emphasis they put on data ethics, through:
- Data governance
- Model assessment to avoid biases and discrimination before deployment
- Model interpretability and explainability
Full list of topics covered
- Synergey of Digital Transformation and AI: Powering Organisational Growth
- Embarking on a Journey to Democratise AI at Scale
- Make Data Science a Team Sport
- The Emergence of AI
- Revolutionising Customer Experience with Conversational AI
- Automation in Data Management: Enhancing Efficiency & Saving Time
- AI and Data Driven Decision Making Panel Discussion
- Generative AI: A Game Changer?
- The Why, Where and How of Enterprise AI Adoption
- Sustainable AI for Humanity
- Blockchain for Healthcare
- Emergence of Web3 and Gaming and Virtual Worlds
- Building Trustworthy and Ethnical AI Panel Discussion
- Securing the Future of AI: Addressing Privacy, Security, and Compliance in LLMs

Opening event to World AI Show
Opening event to World AI Show
2nd August - 🛠️ dbt meetup
I learnt about SQL-centric data engineering at a dbt SG meetup. Two Data Engineers from Teleport showcased how dbt revolutionised their workflow, with the following examples:
- Rapid SQL compilation and query times
- Ability to data version control
- Automating freshness checks
- Optimising clustering and partitioning tables to reduce cloud computing costs and dashboards loading times
- Change logs which makes changes transparent and trackable with Git - allowing for asynchronous collaboration
- Project structure is a more organised as models can be stored
- Aligned logic being inbuilt into tests to ensure smooth pipelines
- Preprocessing and feature engineering with Jinja templates
- Deployment and monitoring - can easily toggle between real-time streaming and batching of data
I’ll definitely be experimenting with this open-source tool and seeing how it can applied to my future workflows.
3rd August - 🧠 How to break into AI Careers
Thu Ya Kyaw (SideQuest founder), Koo Ping Shung (co-founder of DataScienceSG) and Poh Wan Ting and Michelle Lim (Mastercard Lead/Senior Data Scientists) shared their unique journeys on How to break into AI careers. My takeaways were:
- To focus on impact and ROI by productionising models and deploying Proof of Concepts - as model development is only makes up 10% of a data scientists role, the rest of the time is spent on cleaning data, exploring data, deployment code, and maintenance.
- To have good fundamentals of writing production-ready scalable code, testing code, statistics, and being able to explain models.
- Learn how to learn (pedagogy), have good time management, and have a growth mindset to be a great data scientist
- Newsletters are a great way to keep up to date with the latest data science advancements, such as MIT Technology Review, Data Engineering Weekly, TLDR AI, and Koo’s substack.
16 August - 👷♂️ OCBC Data Engineering Revolution
Periyasamy Sivakumar gave a great deep dive into OCBC’s modern Data Engineering tech stack, at Data Engineering SG meetup. This tech stack consists of:
- dbt for rapid SQL compilation
- trino for virtualisation and efficiently serve data from multiple data platforms through a single entry point
- and, dagster for the data orchestration and to handle dependencies.
It was great to hear the full story on:
- What the problem was - OCBC have so much data (4000TB), 90K daily jobs, 1M attributes, so they needed a scalable and controllable solution.
- Why these tools were selected:
- You can write SQL in dbt, compile and run it in Trino, this alone can manage your entire data lifecycle.
- Jobs can be rerun should there be errors, such as network errors.
- The considerations in tool selection:
- OCBC have lots of legacy systems so it takes time to migrate 20 years of business rules.
- OCBC have an in-house team looking for new technology solutions.
- The future of data engineering being real-time streaming:
- In banking - every millisecond counts to help the customer, for example fighting fraud.
- Kafka for data API and Flink for real-time processing.
- The downstream AI/ML use cases:
- Hyper personalisation
- Nudges - send customers mobile notifications to do their tax returns
- Chatbots
- Real-time fraud detection, money-laundering detection
- Real-time assistance - imagine your card was swallowed by an ATM you could receive an SMS with advice, rather than calling a call centre

How OCBC utilise data
18 August - 🦅 Launch of BrightRaven.ai
Celebrated Singapore’s newest AI startup BrightRaven.ai fantastic launch party at the Mondrian Duxton. It was great mingling with Bertrand Lee (founder) and co and hearing their wealth of experience, whilst enjoying the rooftop view! Best wishes to the team on their AI consultancy journey!
21 August - 💵 Application of ML and GenAI in Finance with Fullerton Fund Management
Kai Xin (co-founder of DataScienceSG) wonderfully explained the LLM stack using a burger analogy. Where the bun is analogous to the static components, such as prompt engineering and Retrieval-Augmented Generation (RAG), and the burger patty representing the re-useable components that can be swapped for different ‘flavours’ of fine-tuned LLM models. This is made possible through the use of adapters which can identify and switch to the correct fine-tuned model based on the user input. Kai Xin’s slides can be found at bit.ly/practical-genai-ft.
Kai Xin also showed easy it is do to Practical Generative AI Fine-Tuning. In his live-demo he fine-tuned a Flan-T5 model for financial sentiment analysis in just 8 minutes for free in a Colab notebook, using HuggingFace’s implementation of Quantised LoRA (QLoRA).
Chao Jen shared how they use clustering models to model the Global Macro Regime in combination with a second model for regime transitions - to help their portfolio managers with asset relocation by considering the current global situation. The model outputs were very clearly and intuitively visualised by stacked bar charts showing the probability distributions for each regime. It was impressive to hear how they’ve trained 1000s of models, but there is still a strong need for domain knowledge and judgement between the data scientists and portfolio managers.
Shi Hui shared the importance of using time-based cross-validation for predicting winners in the stock market - not to use Scikit-Learn’s method which can introduce bias and has a limitation of assuming one observation per day. For this type of analysis, ideally you’d have at least two cycles of the economy, so at least 5-7 years. Some useful predictive external signals include estimates data for company fundamentals, news sentiment, and investor company visits.
Yan Rong shared how to predict the U.S. Treasuries Yield Curve with PCA Decomposition for global market simulation. YTC is the rate that U.S. banks can borrow money. Yan Rong showed how you can reduce from 11 features to 3 components and still capture 99% of the variance. You can isolate these components in line charts to understand the intuition in the YTC movements and do scenario simulations. The code and slides by the Fullerton data scientists can be found at https://github.com/shihuiFFMC/dssg_aug2023.
Kai Xin summarising the LLM landscape
29 August - ⚛️ Data Tuesday #2 - Quantum Computing
Caught up again with some familiar faces and also new faces at The Terrace again, this time discussing Quantum Computing. Some thoughts that I left with:
- Quantum computing is still many years from being practical and decrypting our modern encryption algorithms, like RSA. But we may begin to see services offering quantum computing encryption in the near future.
- Quantum computing won’t create as many startups as GenAI - due to the barrier of entry being so high - requiring millions of R&D in hardware, software, and algorithm development, versus GenAI where the cost of entry is so cheap.
- How AIs in the western world already differ versus China and will continue to drift apart. LLMs are predominantly trained on data in the languages of their associated markets, so there are already substantial differences and biases from the model pretraining. Next, there will be differences due to activity and advancements from their respective open-source community. This split is further exacerbated with the U.S. restrictions on advanced AI chips, like A100, on China and Russia, where these AI researchers will be unable to build upon the latest architecture.
- Will NVIDA maintain its dominance in the AI GPU space? Or can the cheaper alternatives from AMD, Intel, or China (if they aren’t sanctioned) can compete? A big reason for NVIDIA’s dominance is because they were first-to-market in the space and the open-source community has developed everything on their architecture. Ultimately it depends on how much development there is in porting to non-NVIDIA architecture. Perhaps due to NVIDIA’s inability to meet demand, companies may be forced to resort to competitors.
31 August - 🔍 Why Vector Search is Important
Yoshi Kimoto from Datastax explained Why Vector Search is Important for LLMs. Yoshi explained how:
- Lack of context is the major reason for hallucinations.
- Any data that could be contextually relevant can be vectorised using embeddings.
- Vector search allows for efficient content retrieval from your existing data.
- Vector search allow LLMs to find similar content in large document collections, using linear algebra techniques such as cosine similarity and dot product.
- With storage attached indexing, Lucene can be used for document retrieval in combination with vector similarity search
- Datastax is built on Cassandra and can handle data streaming and ingestion, which opens the possibility for LLMs with the power of real-time RAG.
You can test Datastax’s vector search demo in your browser here.
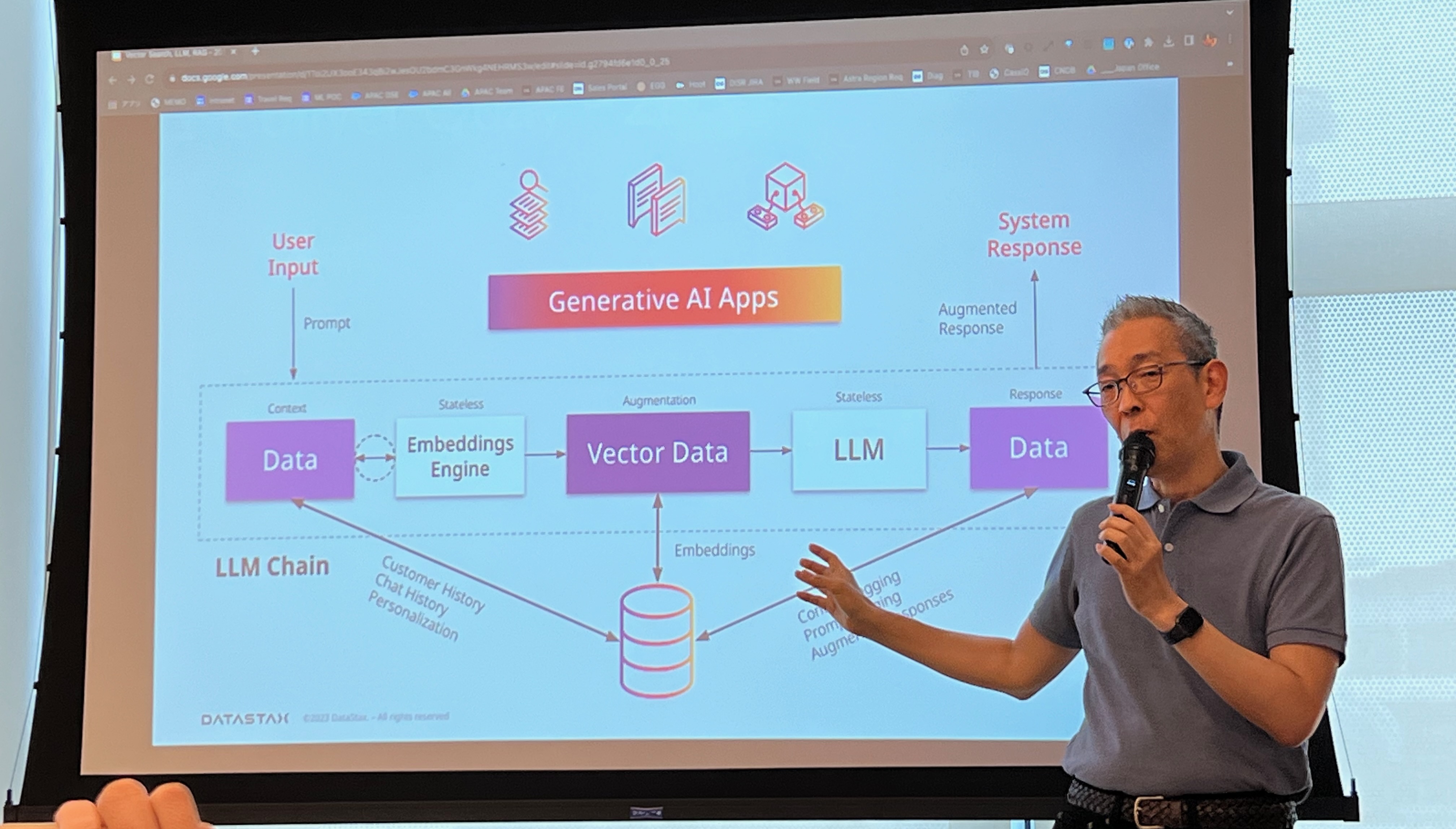
Yoshi on the LLM stack
Wrapping up
It’s been a whirlwind month, and it’s been energising to learn and mingle with the brightest AI minds in Singapore. I’m looking forward to applying these insights and sharing more with you all. After all, education without action is simply entertainment!
Lastly, a big thanks to my talented ex-colleagues in the UK civil service at the Department of Health and Social Care for having me in your teams Lucy Vickers, Phil Walmsley, Mariana, Graeme, and Anita Brock.
Thanks for reading and making it all the way down here! If you fancy a chat about any of these topics, drop me an email.
Cheers!
Vince